
Summary
Spatial weights matrices, W, represent potential interaction between all i, j in a study area and play an essential role in many spatial analysis tasks. Commonly applied binary adjacency algorithms using decomposition and tree representations scale quadratically and are ill suited for large data sets. We present a linearly scaling, adjacency algorithm with significantly improved performance.
Description
Spatial weights matrices, W, play an essential role in many
spatial analysis tasks including measures of spatial association,
regionalization, and spatial regression. A spatial weight
wi, j represents potential interaction between each
i, j pair in a set of n spatial units. The weights are
generally defined as either binary wi, j =
1, 0
, depending
on whether or not i and j are considered neighbors, or a
continuous value reflecting some general distance relationship between
i and j. This work focuses on the case of binary weights
using a contiguity criteria where i and j are rook
neighbors when sharing an edge and queen neighbors when sharing a
vertex.
Population of the W is computationally expensive, requiring, in the naive case, O(n2) point or edge comparisons. To improve efficiency data decomposition techniques, in the form of regular grids and quad-trees, as well as spatial indexing techniques using r-trees have be utilized to reduce the total number of local point or edge comparisons. Unfortunately, these algorithms still scale quadratically. Recent research has also shown that even with the application of parallel processing techniques, the gridded decomposition method does not scale as n increases.
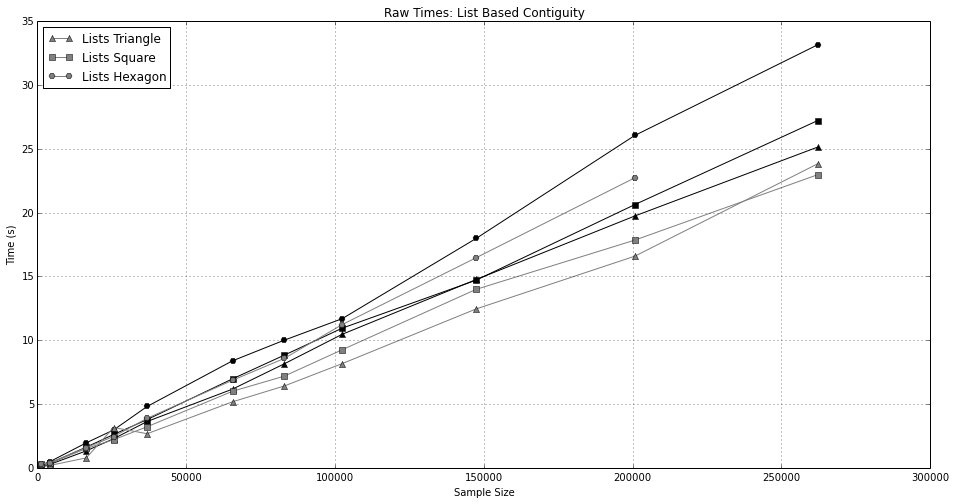
This work presents the development and testing of a high performance implementation, written in pure Python, using time constant and O(n) operations, by leveraging high performance containers and a vertex comparison method. The figures below depict results of initial testing using synthetically generated lattices of triangles, squares, and hexagons with rook contiguity in black and queen contiguity in gray. These geometries were selected to control for average neighbour cardinality and average vertex count per geometry. From these initial tests, we report a significant speedup over r-tree implementations and a more modest speedup over gridded decomposition methods. In addition to scaling linearly, while existing methods scale quadratically, this method is also more memory efficient. Ongoing work is focusing on testing using randomly distributed data, and U.S. Census data, the application of parallelization techniques to test further performance improvements, and the use of fuzzy operator to account for spatial error .

raw times

speedup

linear speed
{kind=link}
{kind=link}
{kind=link}